Transkernel 笔记
智能设备的普及,伴随着硬件性能的提升和丰富多彩的应用软件被开发,人们可以轻松地在智能设备上(例如智能手机、平板、智能手表)完成很多事情。为了使用户有更好的使用体验,操作系统在各种资源分配、调度上花费了心思。如今,各种常用的应用设计逐渐工具化,主打一个轻量,易于使用。这也就导致了在操作系统上,有非常多的小任务(task)。一台设备的处理器数量往往是有限的,为了让用户感觉像是所有程序都是并行执行,操作系统系统就需要不断在各个任务之间进行调度。调度是一个不小的开销,尤其是遇到 IO 设备相关的操作(IO 设备速度远远慢于处理器速度,导致处理器产生非常多的空周期)。这会导致一些不必要的能源(例如电池的电能)消耗。
如何提高处理器执行效率的同时又可以降低对能源的消耗,是这篇论文研究的目的。
1 引入
1.1 能源消耗
由于各种各样的周期性或者是后台活动,现代的嵌入式平台需要执行大量的短暂性的任务。有研究表明,各种智能设备的电池电量有 30% 都是监视类活动所消耗的。像现在的庞大的商业化操作系统(例如 Linux、Windows),恢复(resume)和暂停(suspend)相关硬件平台的能源消耗可能高达用户代码的 10 倍。
1.2 性能
最近的研究表明,性能瓶颈主要是内核的两个阶段,设备的暂停(suspend)和恢复(resume)。这个阶段要完成大量的 IO 相关操作,例如驱动、清理 IO 事件队列以及保证设备达到所期望的能耗状态。这些阶段也主要围绕驱动并发执行、推迟功能和设备中断。这些需要大量 CPU 的时间,而且被证明很难做出优化。
1.3 微控制器
微控制器(microcontroller / MCU)是一种紧凑的集成电路,设计用于管理嵌入式系统中的特定操作。典型的微控制器在单个芯片上包括处理器、存储器和输入/输出 (I/O) 外设。
微控制器有时被称为嵌入式控制器或微控制器单元 (MCU),广泛应用于车辆、机器人、办公机器、医疗设备、移动无线电收发器、自动售货机和家用电器等设备中。它们本质上是简单的微型个人计算机 (PC),旨在控制较大组件的小功能,无需复杂的前端操作系统 (OS)。
微控制器(microcontroller)具有以下的优点:
- 更低的能源消耗。
- 更高的执行性能。
- 普及度更高(ARM Cortex-M 系列在各种智能设备上广泛使用,或者是作为外围处理器使用)。
当遇到 IO 密集型操作的时候,以上 3 个优势就体现的更加明显。试想可不可以将这些 IO 操作让微控制器执行,而不是核心的 CPU?那么为什么又不将用户代码也放置在微控制器上执行呢?有以下两点原因:
- 用户代码所需要的 CPU 时间少。
- 外围核心需要对复杂的 POSIX 环境提供支持才行。
1.4 挑战
下放一些商用庞大的内核操作具有一些挑战性,例如:
- 不同的微控制器硬件有着不同性能和不同的指令集架构(ISA)。
- 内核非常复杂而且在快速迭代。
如今有的解决方案很多只能解决第一个问题而不能解决第二个问题。亦或者是对内核进行重构,但也会引入很多的兼容性问题也不利于持久维护。
1.5 思路
提出一个激进的设计,取名为 transkernel。通过动态二进制翻译技术(DBT),将不可修改的内核二进制代码翻译成不同微控制器 ISA 架构所对应的指令(或指令序列),并在微控制器中模拟执行,替代原有庞大内核与之相对应的部分。
在计算机领域中,二进制翻译(binary translation)、二进制转换或二进制重新编译((binary) recompilation)是以翻译二进制代码来仿真另一个指令集架构。指令按顺序从原指令集翻译为目标指令集。在指令集模拟等某些情况中,目标指令集可能与源指令集是同一指令集,翻译是为提供指令跟踪、条件断点、热点检测等测试和调试功能。
二进制翻译主要分为静态翻译与动态翻译两种类型。翻译可以由硬件(例如通过CPU中的电路)或软件(例如运行时引擎、静态重编译、仿真器等)完成。
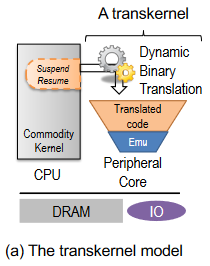
transkernel 的实践性基于以下四个原则:
- 翻译有状态代码,同时仿真无状态内核服务。
- 确定一个狭窄、稳定的翻译/仿真接口。
- 针对热门路径。
- 利用 ISA 之间的相似性。
transkernel 的原型被称之为 ARK(an ARm transKernel)。使用 200 MHz 的时钟频率以及 32 KB 缓存的 Cortex-M3 的外围核心;使用 Cortex-A9 作为主处理器;以 Linux 为操作系统。在此配置上实现了仅支持 12 个 Linux 内核函数和 1 个内核变量的二进制接口。这足以使相关服务稳定运行多年,且完全支持设备的暂停和恢复。
上述的做法满足了功能的需要,保证了可行性,那么这种做法对执行效率和能源消耗的影响是怎样的呢?通过和本地内核执行对比,该方法会导致 2.7 倍的执行开销以及慢 5.2 倍;但是能节约 34% 的能源。
1.6 创新点
Transkernel 对操作系统(OS)以及动态二进制(DBT)翻译有以下贡献:
- transkernel 模型:结合动态二进制翻译以及模拟器,弥合 ISA 之间的区别和处理器之间的不对称性。
- transkernel 实现:ARK。
- ARK 的实践性:跨 ISA 的动态二进制翻译;利用 ISA 之间的相似性来提升性能。
2 动机
论文从内核的设备暂停和恢复、不同的 SoC 的外围处理器的设计以及操作系统的设计空间来发现 transkernel 的一些机遇。
2.1 内核的设备暂停和恢复
在设备暂停过程中,操作系统内核需要维护文件系统的存储、释放用户任务、关闭 IO 设备等事件。这些事件难免会对性能造成损失(用户代码执行的 10 倍)以及更多的能源消耗。之所以这样,是因为以下几点原因:
- 设备的暂停和恢复是低效率的。
- 设备的种类繁多。
- 优化非常困难。
除了上述之外呢,设备的暂停和恢复会涉及到多个内核抽象层。有关这部分的内核代码就多达 154K SLoC,这些代码非常复杂难以理解。
但是我们会发现,设备的暂停和恢复对延迟不敏感;普遍对内核功能的调用都是一些常用的功能(hot path);也不太需要复杂的并行性(这里指硬件的并行性和内核的模块化)。基于这三个特性做一些改进,就可以增加执行时间的同时提升效率。
2.2 SoC 的结构
现在广受欢迎的 SoC 都有着相似的硬件结构,如下表所示:
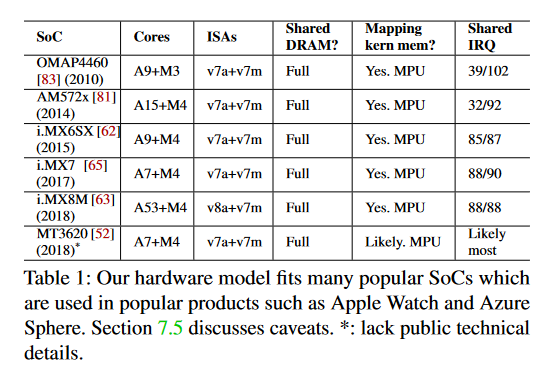
核心处理器和外围的处理器具有以下关系特点:
- 两者基本相互独立。外围处理器具有内存保护单元(MPU)但是不具有地址转换单元(MMU),这就导致了外围处理器不能执行完整的操作系统。
- 虽然两者相互独立,但是他们所使用的 ISA 是相似的。如表 1 所示,使用的都是同一系列不同子集而已。
- 松耦合,但是会共享平台的资源。
外围的处理器都具有比较高的 IO 处理器性能,执行的时候不需要 CPU 的参与,空闲时间所消耗的能源少,结构简单等优点,使其能够达到节约能源的效果。与核心的处理器有相似的 ISA,使其之间的交互变得容易。
为什么 SoC 的不同核的 ISA 具有相似性?
对于 ISA 的设计者来说,各个子集之间的指令语法应当相似(便于硬件解码)。
对于 SoC 的供应商来说,可以简化软件设计,硅片设计,甚至是 ISA 的使用权问题。
2.3 操作系统的设计空间
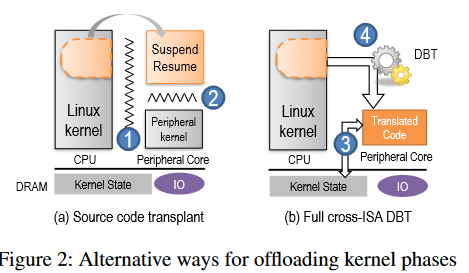
图 2 中展示了两种设计思路,图 2 的 a 的方式是将 Linux 内核中涉及设备的暂停和恢复的部分单独提取出来(重构),并将其编译成外围处理器所支持的 ISA 指令(也就形成了新的外围内核)。其中,会涉及到两个接口,① 和 ②,分别表示两个不同 ISA 之间的接口和外围内核和来自 Linux 内核代码的接口。
对于 ① 接口,需要解决内核数据的独立性。然而 Linux 内核数据和外围内核的数据交互,会受到 ISA 的选择、内核的配置、内核版本等因素的影响。需要对内核代码和配置进行频繁的调整来适配,这样的工作是令人疯狂的。
对与 ② 接口,需要解决功能独立性。Linux 内核跟设备相关的功能函数可能就多达数百种,而且还在不断地更新。维护这样一个接口也是非常困难的。
综上所述,外围内核需要较强的独立性,不依赖于 Linux 内核。于是就有了图 2 的 b 方式,我们直接使用 Linux 内核中成熟的设备相关代码,将其通过 DBT 技术 ④ 翻译成外围处理器所支持的 ISA。这样译码后,外围核心也可以直接操作内核状态 ③。
图 2 的 b 方式也存在一些问题:现有的跨 ISA 的 DBT 开销很大;对整个 Linux 进行 DBT 也很复杂,且外围处理器难以提供软件和调试支持。
2.4 设计目标
- 复用已有的内核资源。
- 构建一次,多处使用。
- 低开销。
3 Transkernel 模型
transkernel 由两大部分构成:1. 用于翻译和执行不可修改的内核代码的动态二进制翻译引擎;2. 模拟的最小化的内核服务。

transkernel 也遵守以下 4 个原则:
- 翻译有状态的代码,模拟无状态的服务。像设备驱动、驱动库和一小部分内核服务,可以直接使用内核原有的代码,将其翻译成外围处理器所支持的 ISA。对于没有状态的一些内核服务,可以用模拟执行,不需要和内核的状态进行交互。
- 发现少量稳定的翻译和模拟的二进制接口。这些接口不受内核配置的影响,且长期不会发生变化。
- 仅针对热路径。大部分情况下,都会执行一些常用的功能。可以针对这一部分进行优化。其他较冷的路径,就可以交给原 CPU 执行。这样也可以使 transkernel 的设计简单化。
- 利用 ISA 的相似性。利用同系列的指令集的语义、寄存器使用以及控制流的相似处。
transkernel 当然也有有一些限制。例如,利用 ISA 的相似性,这一原则对于不同系列的 ISA 就不适用(如 x86 和 arm),反而没有好处。设计机遇中提到了可以降低延迟的敏感性,这一点对一些延迟敏感的操作,如用户的输入,可能就会降低用户的使用体验感。目前可以使用探测的方式,来找到这些延迟敏感的操作,并将其交给原 CPU 执行。
4 ARK 实例
下图展示的是 ARK 的结构。
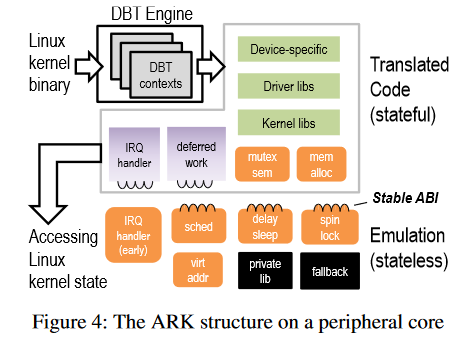
下文中,提到翻译代码都是有状态的事件,模拟都是无状态的事件。这一点从上图中就可以看出。
ARK 是独立于 Linux 的一个内核,能够代替 Linux 完成一些事件。要替 Linux 完成一些事件,我们需要将控制权从 CPU 手中转移到到外围处理器的手中。这个控制权转移过程被称之为 handoff。
由于冷路径被提前定义了,ARK 只会执行热路径。如果是冷路径,会原交给 CPU 来执行。为了能够支持并发性,ARK 维护了数十个 DBT 的上下文,并采用轮询的方式来进行调度。同时,切换这些上下文的开销也非常的小。
除了 DBT 上下文的调度之外呢,ARK 还能完成以下事件:
- 中断和异常处理(模拟):ARK 只支持中断,不支持异常处理。同时,中断也分成内部中断和外部(设备)中断。在内部中断早期的时候是和架构相关的,需要 ARK 先模拟,然后,交付给内核完成剩下的中断处理。对于外部中断,ARK 就直接模拟。由于 CPU 和外围处理器的架构不同,特权寄存器不同,所以如果访问的是 CPU 的特权寄存器,就要抛出错误,并由 ARK 完成相应的错误处理。
- 延迟任务(翻译):ARK 会分配专用的 DBT 上下文来执行这些延迟任务。例如,为每一个中断分配一个上下文;分配一个上下文来执行短时,不需要睡眠的任务(tasklet);为每一个执行队列分配一个上下文,这些执行队列不会阻塞其他执行队列的执行。
- 锁机制:对于自旋锁,使用是模拟的方法。因为在 handoff 期间,CPU 不持有自旋锁。这样我们可以使用屏蔽中断和恢复中断来模拟出自旋锁的效果。而对于睡眠锁,使用翻译的方式,因为是有状态的。
- 内存分配(翻译):ARK 可以像内核一样分配和释放空间,除非遇到内存不够分配的情况(这种情况出现的概率很低)。
- 延迟(Delay)(模拟):通过暂停调用者的上下文来实现 msleep 功能。
- jiffies(一个时间有关变量):唯一和内核共享的变量。使用外围处理器的计时器来测量时间。
5 动态二进制翻译
现在普遍的动态二进制翻译引擎(如 QEMU),都是跨 ISA 翻译。按照事先编写好的翻译规则,将客户指令翻译成对应宿主的指令或者指令块。翻译之后呢,引擎也会将翻译解决缓存在代码缓存(code cache)中,方便下一次直接使用。
ARK 也是基于 QEMU 的二进制翻译器,不同之处在于 ARK 是相似指令集之间的翻译,即 v7a 到 v7m。同时,ARK 也做了以下两点优化:
- 尽可能使用更少的宿主指令。
- 提高代码缓存的命中率。
这些优化主要还是依靠指令集之间的相似之处。
5.1 相似的语义
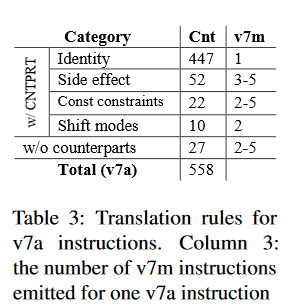
上表展示了从 ARM v7a 到 ARM v7m 转移可以使用的策略。除了忽略一些中断和异常指令外,80% 的指令都可以直接翻译成对应的一条 v7m 指令。15% 的指令仅需要处理一下副作用(Side effect)、常量表示范围的限制(Const constraints)以及位移功能限制(Shift modes),用几条 v7m 指令就能实现相应的功能。最后,也仅有 27 条指令不能直接找到对应的指令,需要自己创建翻译规则。
5.2 相似的寄存器
v7a 和 v7m 都使用着相同的通用寄存器,v7a 的寄存器的数量会比 v7m 多。ARK 使用对内存的存取的方式来替代所有客户的寄存器。由于 v7m 的寄存器少,当模拟一条指令需要使用多条宿主指令的时候,寄存器可能就周转不过来了。此时需要一个临时寄存器。通过对内核代码的分析,发现对 R10 寄存器的使用是最少的,所以选用了 R10 寄存器做为了临时寄存器。
对于条件寄存器,直接使用了客户的条件寄存器,原因是两者是一样的。这样做法也更有利于繁重的暂停于恢复的控制。然而,翻译后的代码可能会影响原有的条件寄存器。为了解决这个问题,要在执行的时候,将条件寄存器保存在临时寄存器中。
5.3 相似的 PC/LR/SP
对于 QEMU 来说,是直接使用了宿主的内存空间以及宿主的内存数组来模拟的 PC,LR 以及栈。当遇到函数调用返回的时候,DBT 就需要在宿主的内存中找到返回的地址,这样的开销是极大的,不能承受。ARK 就直接使用了客户的栈空间;对于函数的调用,直接将返回地址存放在代码缓存中,返回的时候直接从缓存中取出。
对于 CPU 来讲,存储在客户栈里面的代码缓存地址是无意义的。所以,在回退给 CPU 执行的时候,需要将这部分地址转换成对应的客户地址。此外,客户的压栈和弹栈操作可能会影响模拟的寄存器,需要对模拟的寄存器进行及时的同步。
6 回退 CPU 问题
- 推迟工作的回退:回退给 CPU 后,这些任务仍然要继续执行。然而 Linux 内核没有 DBT 上下文相关的部分。解决方法:在 Linux 内核中创建一个线程来接受这些工作。
- 中断的回退:由于 CPU 和外围处理器的架构不同,不能直接交给 CPU 来处理。应有该外围处理器向 CPU 发出一个 IPI 中断,然后 CPU 再进行处理。
7 总结
transkernel 是一种新的内核模型,主要针对原有内核的设备暂停和恢复。利用异构处理器的特点,使用跨 ISA 的动态二进制翻译引擎,将已有的内核代码的有状态部分进行翻译执行,并将无状态的部分提供服务模拟执行,提高执行效率的同时,可以减少对能源的消耗。
参考文献
[1] Liwei Guo, Shuang Zhai, Yi Qiao, and Felix Xiaozhu Lin. 2019. Transkernel: bridging monolithic kernels to peripheral cores. In Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ’19). USENIX Association, USA, 675–691.
[2] microcontroller (MCU). https://www.techtarget.com/iotagenda/definition/microcontroller.
[3] wikipedia.org 二进制翻译. https://zh.wikipedia.org/wiki/%E4%BA%8C%E8%BF%9B%E5%88%B6%E7%BF%BB%E8%AF%91.