Cohort 笔记
1 引入
为了满足用户对性能的需要,片上系统(SoCs)引入了许多高效专用加速器。这样导致了片上系统的异构性越来越强。如今,对编程加速器(Accelerator)的软件抽象会泄露硬件的细节、需要更改数据格式以及手动内存和一致性管理。这种面向硬件的方式极大的损害了通用性,而且需要熟悉硬件来有效地编程加速器。找到一种更高效的管理硬件加速器以及硬件加速器之间的交互是有意义的。一个理想的解决方式应该具有以下特征:
- 一个能在软件和硬件之间高效沟通的普遍灵活的硬件接口。
- 一个基于现有软件抽象的软件范式以减少新增加速器对软件的修改。
1.1 想法
论文提出了一种方式,称之为面向软件的加速(Software-Oriented Acceleration, SOA),强调加速器通信、隔离、基于现有软件范式的内存管理。并使用共享内存做为软件抽象来减小软硬件的开销和对加速器的使用。论文把这个系统称之为 Cohort。
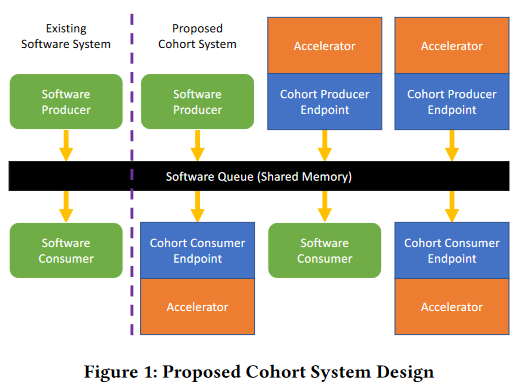
Cohort 模型聚焦于支持 SBIO 通信模式的加速器,并像软件和硬件提供普遍、标准的队列接口,能够复用现有的多线程软件以及硬件而无需对它们进行大修改。
SBIO:流式/缓冲 输入和输出。
1.2 创新点
主要是以下两个创新点:
- 提出了面向软件的加速方法(以往是面向硬件或者是面向加速器的)。
- 队列一致性语义的识别,以实现对软件共享内存队列的有效硬件支持。
2 机遇
现有的软件和硬件接口大多数不具备通用性、灵活性以及易于使用的特点。
2.1 软件
加速器的提供商提供着各种各样的接口(专有编译器和语言、调用特权内核模块、使用供应商专有库)。这导致如果想在各种加速器之间通信是极其困难和脆弱的。
同时加速度器的内存分配和管理也是具有挑战性的。原因有以下几点:
- 加速器使用的各种 IOMMU
- 不同的一致性模型
- 特殊的地址和对齐约束
MMIO 内存映射 IO
将 IO 设备放置在内存空间而不是 IO 空间,对这些 IO 的操作就如同操作内存一样。每个I/O设备监测CPU的地址总线,并且在发现CPU访问被分配到本设备的地址区域的时候做出响应,建立数据总线和相应设备寄存器之间的连接。
然而 MMIO,有特殊的存取语义,该语义会造成性能的影响。并且 MMIO 的副作用会让一些处理器简单地暂停等待其执行完成。这写严重的影响了性能。
2.2 硬件
如今的数据连接接口也使用不同连接方式,有使用 MMIO的,也有使用 DMA的。此外,还使用不同的一致性模型,部分一致性和完全一致性。部分一致性会增加编程的复杂度。完全一致性还存在着缓存一致性的开销。在这两个一致性做权衡也是一件很困难的事情。
在使用 PCIe 的桌面和服务器级设置中,CCIX、CXL 和 CAPI 等协议启用加速器缓存一致性。但是,PCIe 会带来开销和延迟,90% 的延迟由 PCIe 自身产生;此外,像移动平台的 SoC 因为面积和功耗的原因限制使用 PCIe。
CCIX/CXL/CAPI
CCIX (Cache Coherent Interconnect for Acceterators)是用于加速器缓存一致性的协议,目的是需要比当前技术更快的互联,并且需要缓存一致性,以便在异构多处理器系统中更快的访问内存。相关工作集中在使硬件加速器以缓存一致的方式使用与多个处理器共享的内存。该文章中还有对缓存一致性的介绍[3]。
CXL(Compute eXpress Link)是一个开放标准,其高速互联技术可以为高性能数据中心计算机提供高速、大容量的中央处理器(CPU)至设备,CPU至内存,及设备至设备的连接。CXL 作为一种高速串行协议,基于 PCIe 的物理和电气接口构建。CXL 包括基于 PCIe 的块输入/输出协议(CXL.io)以及用于访问系统内存(CXL.cache)和设备内存(CXL.mem)的新缓存一致协议。
CAPI(Coherent Accelerator Process Interface)是个高速处理器扩展总线协议,应用于大型数据处理中心。目的是让 CPUs 和加速器可以直连。
3 Cohort 的解决方法
SOA 提供了面向用户模式,为应用程序和语言运行时提供了更大的灵活性、隔离性和安全性。在用户级的操作下,不应该使用上下文切换和内核交换操作。
同时,使用共享内存队列作为通用语,使用普通的生产者消费者模型作为抽象以提高可编程性以及可组合性;使用加速器替换现有的去耦的软件线程,同时维护现有代码和链接生产者和消费者的队列链。
目前,在开发高性能的无锁队列库方面已经付出了很多努力,这些库通过减少一致性作用并利用现代处理器内存级的并行性来提高性能。论文在此处聚焦于无锁单生产者消费者队列(SPSC,single processor-single consumer),并向将队列操作连接到缓存一致性系统的引擎上来保证队列一致性。
Cohort 使用 Cohort 的引擎替换了软件线程,这个“加速器线程”和软件线程的通信和其他软件是一样的。Cohort 接管了计算部分,通过两个软件队列,分别传递计算的输入给加速器和获取加速器的计算输出。这样做法,也使得几个加速器之间的亦或者是软件之间的计算变得透明。
4 Cohort 的实现
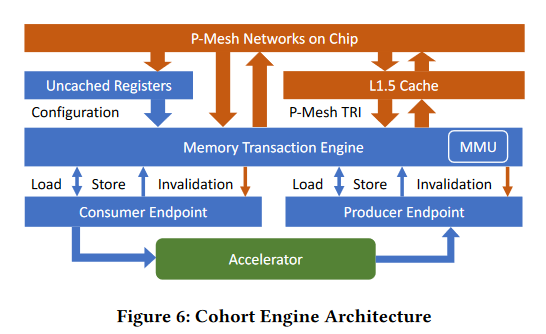
Cohort 引擎的架构图如下图所示:
4.1 编程模型
Cohort 设计在用户模式下使用,最小化操作系统的参与。
为了能够在 Cohort 上注册一个队列,需要一个结构体来描述配置 Cohort 队列的属性。属性包括元素的大小、队列的大小、读写指针。把描述这些信息结构体,称之为队列描述符。
write_pointer/index
read_pointer/index
fifo_base_address
fifo_element_size
fifo_lengthCohort 也为用户编程提供了两个 API,cohort_register和cohort_unregister,分别在一个加速上注册两个队列和注销两个队列。这两个队列通过fifo_init传递队列描述符来进行初始化。其他相关的队列操作可以直接复用已有成熟的队列库(例如 C++ Boost Lockfree library)。
4.2 Cohort 引擎
Cohort 使用延迟不敏感的握手 FIFO 和 AXI Stream 将软件级线程安全的队列和硬件队列桥接起来。按照第 3 节所描述的,Cohort 通过把队列相关操作连接到缓存一致性系统上来保证队列一致性。这里的原型引擎使用 OpenPiton 的 P-Mesh 缓存一致性系统(如图 6 的橙色部分)。
图 6 中,蓝色部分表示的 Cohort,绿色部分表示加速器。从图中可以看出,Cohort 由以下几个部分构成:
- 未缓存的配置寄存器:通过该寄存器配置 Cohort,并且是唯一一个 MMIO 模块。
- 内存翻译引擎(Memory Translation Engine)(含有MMU,MMU 基于 RISC-V Sv39 实现):MTU 将上层的内存操作和无效信号(invalidations)转换成物理寻址一致性操作。MTU 内嵌基于本地指令集的 MMU,使得加速器的编程可以直接使用虚拟地址从而简化编程。
- 消费端(Consume)和生产端:消费端通过无效信号(invalidation)来决定是否取出数据给加速器。如果有数据可取,则可以设置有效信号,等待加速器握手(设置 ready 信号)接受。当加速器有数据可以产出时,设置有效信号 valid,等待生产端接受。这些操作的一致性都由缓存一致性系统保证。
Cohort 的队列语义和软件的队列语义是一样的。在 SoC 的微架构中,我们认为缓存一致性系统会使其他缓存的缓存行变得无效,这一行为可以视为一个对 Cohort 的信号,使其获取更新的数据。读一致性管理者(RCM)会监视通过未缓存的寄存器的地址以及传入的无效信号。如果无效信号和地址想匹配,则会进入一个暂停阶段,这个暂停阶段的长度由暂停单元控制。当这个阶段结束的时候,就会使用一致性读来处理最新的数据。这里的一致性由写的顺序来保证。
4.3 加速器接口
加速器通过握手协议和消费端和生产端相连,生产数据的接口宽度可以不和消费数据接口的宽度。具体的数据交互方式如 4.2 节中关于消费端和生产端的描述。
4.4 操作系统支持
Cohort 提供一个内核驱动来建立一个完整安全的数据流和向用户隐藏硬件细节。该驱动有以下几个特征:
- TLB flush 的 MMU 通知器:用于管理 TLB 的一致性。
- 缺页错误通过中断进行重定向:当 MTE 中的 MMU 遇到缺页错误,触发中断,调用 Cohort 内核驱动注册的处理函数进行处理。
- 使用 Cohort 注册队列:当用户应用想要注册一个 Cohort 时,会映射 Cohort 的配置寄存器区域、注册 MMU 通知器和缺页处理函数。然后,向 Cohort 写入队列描述符。至此,Cohort 就可以使用了。
- 注销队列:通过对上述资源的解除分配和映射即可。
4.5 Cohort 的能力和扩展性
Cohort 可以加速处理器内部的通信;同时,使用加速器链(加速器之间使用 Cohort 队列(SPSC)串联起来),可以很好地加速计算。Cohort 目前还不支持多消费者和多生产者的模式,使用该方式会产生原子操作问题。
5 总结
Cohort 使用面向软件加速的方式,优化软件和硬件的接口,使得软件和异构加速器/异构加速器之间可以高效地连接起来。使用软件抽象——共享内存,来连接各个部分。加速器或者是软件的数据计算或者是使用,使用了普通的生产者消费者模式,用队列传输得以实现。软件层提供了丰富的队列操作支持,简化了程序开发。同时,队列一致性交给了缓存一致性系统(P-Mech cache coherence system)来保证。硬件使用握手 FIFO 或者 AXI Stream 协议来实现通信。
Cohort 在提高性能和 IPC 的同时,也减小硬件资源的消耗。
总之,Cohort 更像是软件和硬件之间的管道,只能单生产者对应单消费者。多对多的形式不支持,因为涉及原子操作,留给了后面的研究。
参考文献
[1] Tianrui Wei, Nazerke Turtayeva, Marcelo Orenes-Vera, Omkar Lonkar, and Jonathan Balkind. 2023. Cohort: Software-Oriented Acceleration for Heterogeneous SoCs. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS 2023). Association for Computing Machinery, New York, NY, USA, 105–117. https://doi.org/10.1145/3582016.3582059
[2] wikipedia.org. 存储器映射输入输出. https://zh.wikipedia.org/wiki/%E5%AD%98%E5%82%A8%E5%99%A8%E6%98%A0%E5%B0%84%E8%BE%93%E5%85%A5%E8%BE%93%E5%87%BA
[3] synopsys.com. CCIX 简介. https://www.synopsys.com/zh-cn/china/resources/dwtb/dwtb-cn-introduction-to-ccix-2017q4.html
[4] wikipedia.org. Compute Express Link. https://zh.wikipedia.org/wiki/Compute_Express_Link
[5] wikipedia.org. Coherent Accelerator Processor Interface. https://en.wikipedia.org/wiki/Coherent_Accelerator_Processor_Interface
[6] OpenPiton. Enhancing the Open-Source P-Mesh Cache Coherence System for Open ISAs. https://ics2020.bsc.es/sites/default/files/uploaded/jbalkind-pmesh-final.pdf