最近在同一平台上集成多个操作系统、高核数、异构ISA处理器的可能性提出了一个问题:考虑到系统组件之间的紧密集成,是否可以采用共享内存编程模型,增强可编程性?
1 摘要和引入
如今,异构计算的格局正在发生变化。在硬件层面,不再是主处理器和平台环境进行专有组合适配,而是采用多核数多处理器的方式。在软件层面,每个应用都是 OS/ISA 相关的,除非使用异构编程库(如 OpenCL, MYO)或者是分布式内存编程模型(如MPI)。
什么是 MPI ?
对 MPI 的定义是多种多样的,但不外乎下面三个方面,它们限定了 MPI 的内涵和外延:
- MPI 是一个库,不是一门语言。MPI 提供库函数/过程供 C/C++/FORTRAN 调用。
- MPI 是一种标准或规范的代表,而不特指某一个对它的具体实现。
- MPI 是一种消息传递编程模型。最终目的是服务于进程间通信这一目标 。
为了提供更好的可编程性,作者实现了一个使用共享内存编程模型以及使用 POSIX 接口的软件架构,以便可在异构系统中运行。同时,利用了应用之间工作量的多样性,将不同工作量的应用代码交付给不同异构系统中的处理器群(processor island)来执行,从而提升性能。
新兴的异构平台的特点就是高耦合多 ISA 的处理器群,每个处理器群都有独立的 ISA 和内存一致性域。为了能在异构系统中透明高效地执行应用程序,作者提出了在不同处理器群之间提供共享内存,并利用 ISA 的多样性,将不同代码块分配到最适合的处理器群中运行。
该论文主要探讨 Xeon – Xeon Phi 异构平台。两个架构之间的差距越大,就需要完成更多的工作使应用可以在多个处理器群中运行。
2 动机
非共享内存的编程范式造成了很大的麻烦,限制了程序员的表达能力,以及破坏了每个平台的操作系统模型。目前有两种解决方法来支持多操作系统的处理器群:
- 应用程序分解:应用程序被加载在一个处理器群上,每当一个代码块被分解时,该块和它正在工作的数据被传输到另一个处理器群。分解的计算由运行时和编译器编译成对应处理器群的指定 ISA,并和处理器群的应用整合。程序员必须亲自对应用程序进行分解和决定交个给那个处理器群执行。分解操作破坏了共享内存范式,并且额外增加寻找最佳代码分解的工作。
- 分布式内存编程模型和分区全局地址空间(PGAS):如今大多数应用程序都使用的共享内存编程模型。重写这些代码(大约 44% 的代码都需要重写)的工作量是极其繁重的,而且容易犯错。
现有方法的局限性,促使 Popcorn 的想法的提出,解决异构 ISA 平台和开发者之间的鸿沟,提高生产力。Popcorn 使得为同构 ISA 多处理器编写的多线程共享内存应用程序可以在异构 ISA 的平台上运行。同时,为应用程序透明地提供分布式共享内存(DSM)。
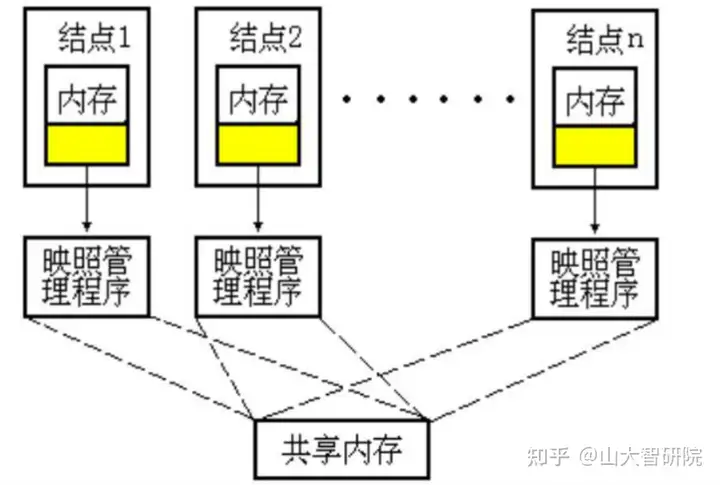
什么是 DSM ?
分布式共享内存提供给程序员一个逻辑上统一的地址空间,任何一台处理机或节点都可以对这一地址空间直接进行读写操作。具有分布式内存结构可扩充性的优点,也具有共享内存结构通用性好、可移植性、编程容易的优点。
而对于编译器框架,现在 Linux 的主要编程方式还是针对于一个特定的 ISA, 并将代码编程该 ISA 的二进制文件。目前已有的异构系统的解决方式是,使用中间语言和嵌入式目标独立(embedded target-independent)的的中间形式。Popcorn 没有采用这些方法,而是单独提供二进制解决方案,同时支持多种架构,并允许在特定迁移点切换架构。
这篇论文有以下两个创新点:
- 操作系统:第一个基于 Linux 的,在异构 ISA 平台上运行的复用内核操作系统。
- 编译器框架:该框架可以转换共享内存程序,使它们可以在不同的处理器群中迁移和执行。
3 Popcorn 架构
Popcorn 的目的是在一个高耦合多样的处理器群中,表现出只有一个执行环境的假象,允许应用程序为代码块选择最适合的处理器群进行执行。Popcorn 有以下 3 个设计原则:
- 透明的:用户可以完整的看到并使用整个平台资源而没有障碍,从而可以专注于 SMP 系统的应用程序的逻辑实现。
- 加载共享:使用潜在的多架构代码,使得应用程序可以在任意处理器群上执行。
- 利用不对称性:我们应该利用每个处理器本地资源以及处理器微架构的不对称性。
3.1 硬件模型
Popcorn 的硬件模型如图 1 下方黑白部分所示,目的是为了抽象出现有的新兴的硬件。
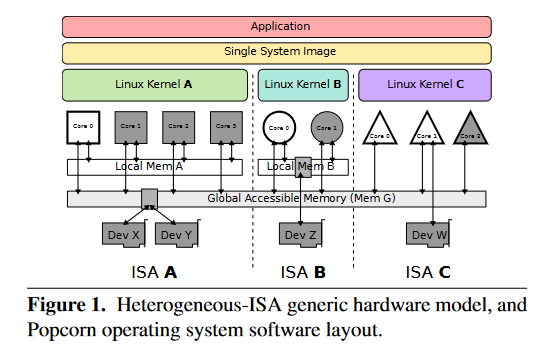
Popcorn 假设每个处理器群的每个处理器的 ISA 都是同一家族的 ISA 。正如图 1 中的 ISA A,ISA B,ISA C 所示。所有的处理器群都有一个共享的,最终一致的存储器,如图 1 中的内存 G 所示。每个处理器群也可以有自己独立访问的内存,如图 1 中的内存 A 和内存 B 所示。在图 1 中,设备 X 和 Y 是可以被任意处理器访问的,而设备 Z 和 W 分别只能被处理器群 B 和处理器群 C 访问。
3.2 软件层次
Popcorn 的软件层次如图 1 上方的彩色部分所示,将一个应用程序使用 Popcorn 的编译框架进行编译,并在 Popcorn 操作系统上运行。
3.3 操作系统架构
操作系统由多个不同内核构成。每个内核都有与之相应的架构和处理器群,同样如图 1 所示。内核给应用程序一个假象,就是在这些不同的处理器群上只有一个操作系统,而且应用程序可以在这些处理器群之间迁移执行并且共享硬件资源。如果内核之间没有硬件缓存一致共享内存,Popcorn 就提供了软件的分布式共享内存,这样,基于多线程的共享内存应用也可以工作。
Popcorn 提供了一个通信层(communication layer),将不同 ISA 的内核连接在一起。如图 2 所示:
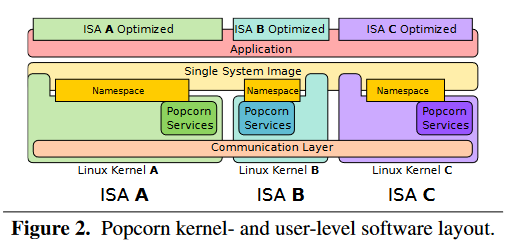
图 2 中展示的 Popcorn 的服务层(services)和命名空间层(namespace),为操作系统在多个内核执行创造了一个环境,也使得应用程序认为,他们是在一个对称多处理器的操作系统上执行的。当应用程序在多内核之间执行的时候,程序的状态会被复制迁移,以保证一致性。
3.4 编译器支持
Popcorn 的编译器框架将应用程序的源代码作为输入,经过一系列离线分析和分析,结合预先构建的硬件平台知识,生成可以在 Popcorn 操作系统上运行的多 ISA 二进制文件。编译器需要满足以下两点需求:
- 生成可以在异构操作系统上执行的应用程序。
- 能在复制的操作系统上利用最佳的应用程序工作负载划分。
Popcorn 单独提供二进制解决方案,同时支持多种架构,并允许在特定迁移点切换架构。该处理器框架会选择在迁移时有可能提升性能的代码块,并且插入代码来与内核交互,以便在那时选择性地执行跨架构的迁移。
4 Popcorn 的实现
Popcorn 在 Xeon – Xeon Phi 的异构 SoC 上实现的。
4.1 操作系统
复用现有的操作系统内核,分别部署在 Xeon 和 Xeon Phi 的核上。之所以直接复用现有的核,是想让总多现有的应用程序可以在 Popcorn 上执行。
4.1.1 消息架构
Popcorn 提供了内核级、可插拔的、低延迟的内核消息层。使用 MPSS 的 SCIF 完成 Xeon 和 Xeon Phi 核之间的通信。
4.1.2 命名空间
Linux 提供命名空间是为了达到提供轻量虚拟化的效果。Popcorn 对此进行了重新设计,以达到在每个内核中,都可以看到所有可以利用的资源。
4.1.3 任务迁移
Popcorn 在 Linux 内核内部引入了用户空间的迁移任务。为了使任务的迁移更加的高效,Popcorn 在每个内核上实现了一个虚设的任务池。当有任务迁移发生时,就将在虚设的任务池中睡眠的任务唤醒。这样就可以提高迁移的效率。
4.1.4 一致性服务
Popcorn 使用页面复制算法、文件描述符算法、快速用户锁(Futex)算法来提供一致性服务。
Futex
futex(快速用户区互斥的简称)是一个在Linux上实现锁定和构建高级抽象锁如信号量和POSIX互斥的基本工具。
Futex 由一块能够被多个进程共享的内存空间(一个对齐后的整型变量)组成;这个整型变量的值能够通过汇编语言调用CPU提供的原子操作指令来增加或减少,并且一个进程可以等待直到那个值变成正数。Futex 的操作几乎全部在用户空间完成;只有当操作结果不一致从而需要仲裁时,才需要进入操作系统内核空间执行。这种机制允许使用 futex 的锁定原语有非常高的执行效率:由于绝大多数的操作并不需要在多个进程之间进行仲裁,所以绝大多数操作都可以在应用程序空间执行,而不需要使用(相对高代价的)内核系统调用。
4.2 编译器架构
编译器会选择在函数调用之间进行架构迁移。修改代码只会修改能被修改的代码的部分而不会去修改不能修改的代码部分。
为了让编译器寻找最合适的划分块,Popcorn 提出了一个消费模型(Cost Model)。论文举出的一个例子如下:
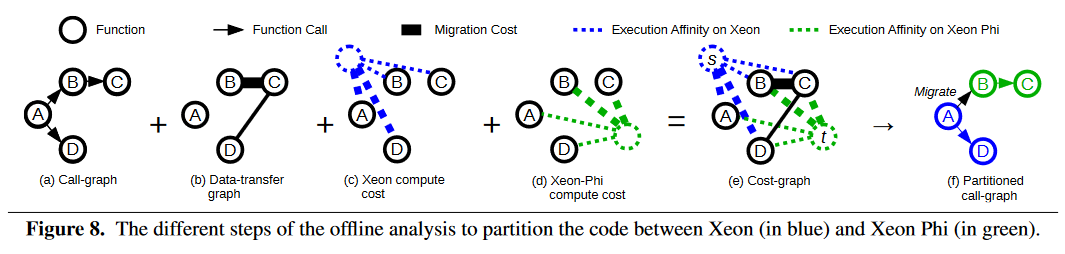
图(a)中表示一个程序功能之间的调用关系;图(b)表示在函数调用之间如果发生了架构迁移,数据复制所产生的消耗,线越粗,表示复制所产生的消耗约大。
图(c)和图(d)分别表示每个函数对 Xeon 架构以及对 Xeon Phi 架构的亲和度,线越粗,表示亲和度就越高。如果在亲和度高之间发生了架构迁移,所产生的开销是非常大的。
前面四个图结合起来就产生了图(e),一个开销图。现在就是需要对这个图进行划分,使得划分的不同区域之间的开销和最小。这个问题就演变成了最小割问题了。
最小割
在图论中,去掉其中所有边能使一张网络流图不再连通(即分成两个子图)的边集称为图的割(英语:cut),一张图上最小的割称为最小割(英语:minimum cut或min-cut)。与最小割相关的问题称最小割问题(英语:minimum cut problem或min-cut problem),其变体包括带边权、有向图、包含源点与汇点(简称有源汇),以及将原网络分为多于两个子图等问题。其中,带边权的最小割问题允许有负权边,可通过对所有边权取相反数简单地转化为最大流问题求解。
参考文献
Popcorn: bridging the programmability gap in heterogeneous-ISA platforms