作者都来自 EPFL,24年的 OSDI。
主要介绍了一套工作流和工具 (ltc),用于分析已有的加速器 RTL 代码,得到相应的功能、性能参数,以及生成相应的性能接口和仿真代码。
1 背景
机器学习、视频解析、压缩、加密等复杂应用广泛在数据中心和移动设备上使用。为了提升这些专有应用的速度,现代系统多将这些功能下放加速器,通过硬件的方式提升整体性能。
然而,系统开发者们很难充分地正确地使用加速器,原因是他们不能准确地了解加速器的功能和相应的性能提升,导致不能在软件和硬件之间取得应有的性能平衡。系统开发者可能会遇到以下困境:
- 在系统设计阶段,不清楚那些功能可以下放加速器。
- 在系统实现阶段,不知道如何针对加速器有目的性的优化代码。
- 在系统部署阶段,如何保证整个系统的性能达到要求。
为了解决这些问题,需要一个工具,可视化地展示加速器的功能和性能。
2 贡献
一套工具链 (ltc),基于加速器的 LPN (Latency Petri Net),通过 lpn2pi 工具,生成易于程序员理解的性能接口 Python 代码;通过 lpn2sim 工具,生成加速器的 C++ 仿真代码;通过 lpn2smt,生成 Z3 的形式化验证条件。整个工具链的流程图如下所示。
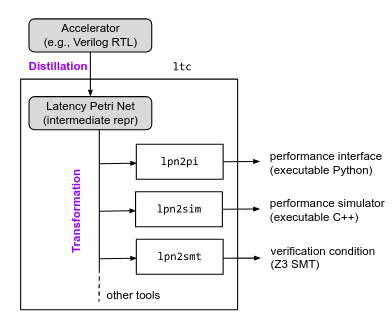
3 Latency Petri Net
整个工具的前期工作,也是最重要的一环,将 RTL 代码生成 LPN。以下图为例。
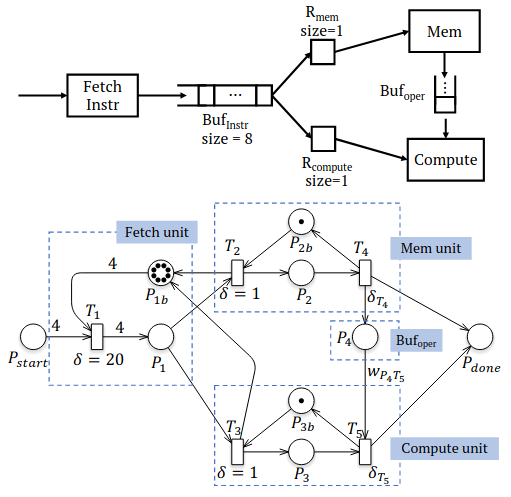
上方是简易的 RTL 描述图,下方是最终分析得到的 LPN。该 RTL 仅是一个简单的取值和计算的过程。取指模块 (Fetch Instr) 从内存中取出计算指令,将其存储在 队列中;然后,内存单元 (Mem) 或者是计算单元 (Compute) 从指令队列中取出指令并存放在内存模块寄存器 () 或者是计算模块的寄存器 () 中。
论文假设,内存模块和计算模块的变量延迟分别为 和 ,内存取指的延迟为20个时钟周期(同时取4条指令);指令队列的大小为8。LPN 有两个元素,节点 (Places,圆形表示) 和转换 (transitions, 矩形表示),每条边只能连接一个节点和一个转换。每个转换都有一个守卫 (guard),决定是否触发转换。
3.1 LPN 定义
LPN 将节点 (places) 定义为队列,将转换 (transitions) 定义为逻辑单元。LPN 有三个类型定义:
- LPN 状态 (state):,为一个元组。 是所有节点 在执行中的信息 (tokens);t 表示当前的时钟值 (CLK)。
- LPN 信息 (token): ,是一组键值对映射,p 为属性值或者理解为参数,ts 表示一个时间戳。
- LPN 转换 (transition):,是一个元组。 表示转换的守卫; 表示转换的延迟; 表示表示转换的功能。
会读取输入节点 (Places) 信息,如果没有达到运行条件,就会返回未准备好 (NotReady);如果达到了运行条件,就会返回使能 (Enable)(为了防止条件竞争,不会同时有两个转换被使能)。即使进入了使能,也不能立刻执行转换,需要等待一定的延迟周期 ()。 将输入节点 (input place) 的信息 (token) 进行功能处理,产生新的信息 (token) 并传递给输出节点 (output place),即 。
3.2 RTL 转换为 LPN
将 RTL 转换为 LPN,需要进行以下5个步骤:
-
将内存和寄存器都替换成节点 (place),将逻辑单元替换成转换 (transition)。
-
定义守卫 (guard) 和相应的进入条件 。
-
规定每个转换的延迟 和生产者功能 。
-
处理一些特殊的单元模块,例如内存。
-
添加起始和结束节点,并设置相应的起始信息 (token)。
4 总结
该论文重点介绍了受 Petri Net 启发而设计的 Latency Petri Net,可以将加速器的 RTL 的代码转化成几乎等价的中间表示形式 LPN,并可以通过3个工具 lpn2pi / lpn2sim / lpn2smt 将 LPN 解析成系统开发者易于理解的形式。虽然该工具不能应用于复杂的内存系统和缓存机制的相关硬件系统,但对于加速器的分析还是足够使用的。通过实验,也证明了该工具可以极大地提高系统开发者的开发和设计效率,充分地利用加速器所带来的优势。